|
Immersitech SDK Documentation
Engage SDK documentation
|
|
Immersitech SDK Documentation
Engage SDK documentation
|
In a 3D audio space we can establish one person as a listener and every sound source they hear can be a source. In the Immersitech Sound Manager SDK, each participant is a listener and each other participant is a source to them.
To achieve the optimal 3D spatial audio quality, the SDK needs to understand what type of physical audio equipment setup the user has. To this end, there are some imm_audio_control settings that allow for this information to be set for each participant.
First each participant will want to set their IMM_CONTROL_DEVICE which tells the Immersitech library the type of device they are using. They should choose to set IMM_CONTROL_DEVICE to IMM_DEVICE_HEADPHONE if they are using any type of headphone such as in-ear, on-ear, or over-ear headphones. If a user has a stereo pair of loudspeakers set up, they should set IMM_CONTROL_DEVICE to IMM_DEVICE_SPEAKER. By default, IMM_CONTROL_DEVICE is set to IMM_DEVICE_HEADPHONE and if a user doesn't have either of these devices or doesn't understand their setup it is recommended to leave this default.
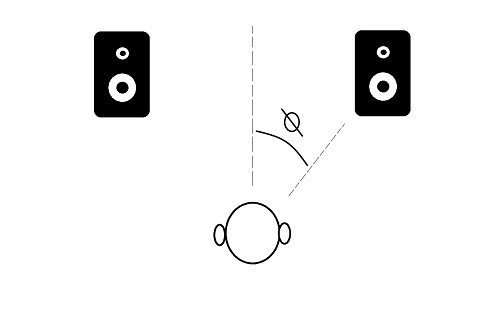
When IMM_CONTROL_DEVICE is set to IMM_DEVICE_SPEAKER, a user must also set up the IMM_CONTROL_HALF_SPAN_ANGLE properly to achieve proper spatial 3D. This parameter is not used when a participant's IMM_CONTROL_DEVICE is set to IMM_DEVICE_HEADPHONE, it only applies for participants that are using speakers. IMM_CONTROL_HALF_SPAN_ANGLE lets the SDK know the relative angle the user is to the physical speakers they are listening to. The angle can be from 1 to 90 degrees (integer values). For quick reference, the following devices may be around the half span angle listed below:
To find the half span angle for your setup, you can measure the distance from your head to your speakers and also the distance between your speakers to calculate the angle as pictured below:
The Immersitech libraries can place each participant into a 3D position, but knowing which axis x, y, and z refer to is important. Moving along the x axis will move a participant left or right, moving along the y axis will move a participant up or down, and moving along the z axis will move participant forward or backward, all three relative to the center point (0,0,0). Also note that the unit describing these x, y, z coordinates is Centimeters. Therefore, a participant at (15,-10,50) is 15 centimeters to the right of the center, ten centimeters down from the center, and 50 centimeters in front of the center.
Another important feature of the Immersitech 3D system is what we refer to as "heading". To know the direction of a source to a listener, we must also know which direction the listener is facing. Given the heading, we have all the information needed to perform an accurate 3D rendering, and so this information will always accompany the position.
The Immersitech library also has several more advanced controls if you would like to fine tune the 3D rendering experience. Note that the following parameter only apply if the IMM_CONTROL_MIXING_3D_ENABLE control is active.
The first is the IMM_CONTROL_MIXING_3D_ATTENUATION parameter. As a source moves further from a listener, its volume will decrease. This parameter allows you to control precisely the drop in decibels that a source will undergo for each additional meter they move away from the source.
The second parameter is the IMM_CONTROL_MIXING_3D_MAX_DISTANCE parameter. This parameter allows you to specify at what distance you would no longer like distance attenuation to occur. This way you can prevent participants from no longer being audible if they move very far away from the listener.
The third parameter is the IMM_CONTROL_MIXING_3D_REVERB_ENABLE parameter. By default, reverb is applied to more accurately localize the source in the room. However, if you don't want the reverb or prefer the sound without, this control will allow you to disable it. Note that the source will still attenuate even without the reverb enabled.
In the Immersitech Libraries, we use the notation where one sample is a single value, one frame contains one sample per channel, and one buffer contains one sample period worth of frames. To learn more about this notation, visit this web resource.
When input and output audio may have different sampling rates, it can be confusing to understand the size of the buffers required. The goal of this section is to explain and provide examples to clear this confusion.
When you initialize the Immersitech Library, part of the library configuration is the sampling rate and number of frames as parameters. These values dictate the format of the audio on the OUTPUT side.
When you initialize any participant using some variant of the add participant function, part of the participant configuration is the sampling rate and number of channels as parameters. These values dictate the format of the audio on the INPUT side.
You will submit audio into the input function with the input format you specified and the Immersitech Library will convert the output audio to the output format specified.
The table below will exercise some examples for 10 millisecond buffers:
| Who | Sampling Rate | Number of Frames | Number of Channels | Number of Samples |
|---|---|---|---|---|
| Library Output | 48 kHz | 480 | 2 | 960 |
| Library Output | 32 kHz | 320 | 1 | 320 |
| Library Output | 24 kHz | 240 | 2 | 480 |
| Library Output | 16 kHz | 160 | 2 | 320 |
| Library Output | 8 kHz | 80 | 1 | 80 |
| Participant 1 Input | 48 kHz | 480 | 2 | 960 |
| Participant 2 Input | 48 kHz | 480 | 1 | 480 |
| Participant 3 Input | 16 kHz | 160 | 2 | 320 |
| Participant 4 Input | 16 kHz | 160 | 1 | 160 |
| Participant 5 Input | 8 kHz | 80 | 2 | 160 |
| Participant 6 Input | 8 kHz | 80 | 1 | 80 |
It is important to also establish here that the Immersitech library currently supports the output buffer size to either be 10 milliseconds or 20 milliseconds worth of data. For an output sampling rate of 48 kHz, this is either 480 frames or 960 frames while at an output sampling rate of 8 kHz this is 80 frames or 160 frames. We also support buffer sizes of 512 or 1024 if your output sampling rate is 48 kHz for some audio systems that only use power of two buffers.
This concept is not critical for starting to use the library, feel free to return to this concept when you need to have side conversations from the main conference. The idea of this feature is that a participant can say something to another participant of the same conference without everyone in the conference hearing them.
You can place any participant in a particular whisper or sidebar room using the IMM_CONTROL_WHISPER_ROOM or IMM_CONTROL_SIDEBAR_ROOM parameters respectively. Note that room 0 means that the participant is not in such a room.
A participant who is not in any whisper or sidebar room will be considered to be in the main room. A participant in the main room will only hear sources that are also not in any whisper or sidebar room. A participant in the main room will only act as a source for listeners in the main room or listeners in any whisper room.
A participant in a whisper room will hear all sources from the main room and all sources in the whisper room. A participant in a whisper room will act as a source only for listeners in the same whisper room.
A participant in a sidebar room will hear only sources in the same sidebar room. A participant in a sidebar room will act as a source only for participants in the same sidebar room as them.
A participant in both a whisper room and a sidebar room will hear all sources from the sidebar room and all sources in the whisper room. A participant in both a whisper room and a sidebar room will act as a source only for listeners in the same whisper room.
A room is a space where participants can hear and speak to all other participants in the room. Each room can have unique attributes that can change the audio experience for the participants in that room. A room will have an associated list of seats that participants can occupy, changing their 3D perspective with respective to the other participants.
A room will also have a center point, towards which all participants will turn to face automatically if they are placed into a seat.
A seat is a pre-defined (x,y,z) position that a single participant can occupy. The seat will also have an automatically generated heading that turns the participant in that seat towards the center point of the room.
If you want to move a participant to a seat that is already occupied, the behavior while be defined by the allowSeatStacking property of the room. If seat stacking is allowed, then both participants will occupy the same position in (x,y,z) space, but have different seat IDs. If seat stacking is not allowed, then the second participant will occupy the same position shifted in the z-axis by the stackDelta property.
If you would like to have complete manual control for the participant's position and heading, use a room that is an Open Room. In an Open Room, participants may be moved any where in the (x,y,z) coordinate system and face any direction. If a participant is moved manually, they are no longer considered to be in a seat.
 1.8.17
1.8.17